Abstract
Learning-based speech compression has achieved promising low-bitrate performance, but many neural speech codecs still describe quantized latents with preset-rate discrete symbols or apply entropy coding only after symbol generation. Such designs decouple representation learning from probability modeling, limiting their ability to exploit the non-uniform usage and temporal dependencies of learned speech latents. In this paper, we benchmark neural speech compression from a rate--distortion perspective and further investigate entropy-constrained coding for low-bitrate speech compression. We first formulate a unified learning-based speech coding pipeline and provide a benchmark-style analysis of recent neural speech codecs, showing that explicit probability modeling remains underexplored in learned speech compression. We then propose ECC, an Entropy-Constrained Codec that combines scalar quantization with a learned entropy model. ECC integrates hyperprior-based side information, channel-wise context modeling, latent residual prediction, and lightweight temporal modeling to estimate latent likelihoods for rate estimation during training and arithmetic coding during inference. To further improve low-bitrate efficiency, ECC introduces entropy skip, which omits highly predictable residual symbols using decoder-available scale estimates without transmitting additional skip masks. Extensive experiments show that ECC achieves a favorable low-bitrate rate--distortion trade-off over conventional and neural codec baselines, reducing BD-rate by 39.9\% on ViSQOL and 76.3\% on PESQ on average over two widely-used test sets. Ablation and diagnostic studies further validate the effectiveness of entropy modeling.
Keywords: Speech Compression, Neural Speech Codec, Rate--Distortion Optimization, Entropy-Constrained Coding, Entropy Model
Overview
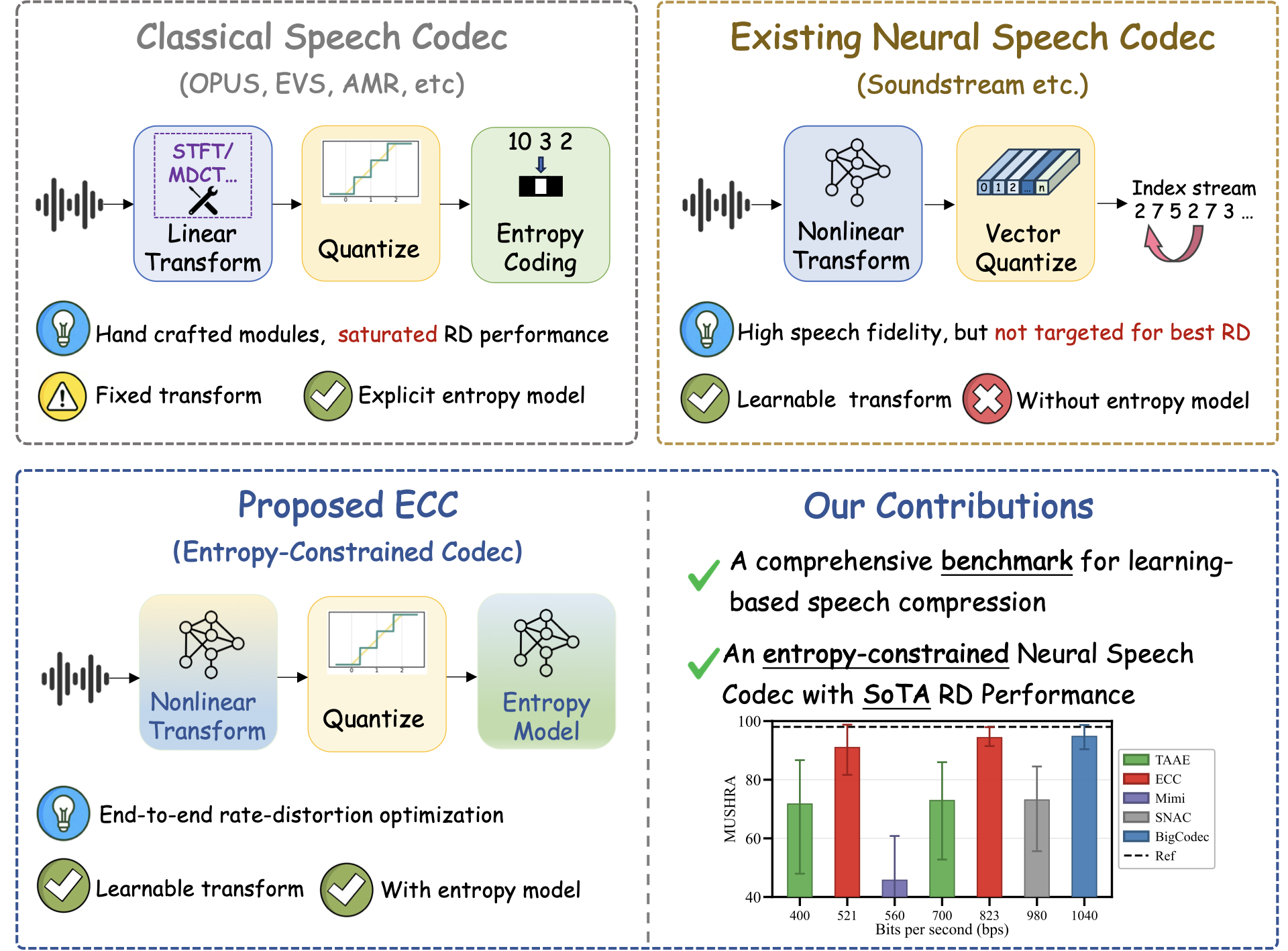
Conventional speech codecs rely on hand-designed transform, quantization, and entropy-coding tools, while recent neural codecs learn nonlinear speech representations from data. ECC bridges these two paradigms by integrating learned entropy modeling into neural transform coding, so that the latent representation is optimized for both reconstruction quality and statistical compressibility.
Figures
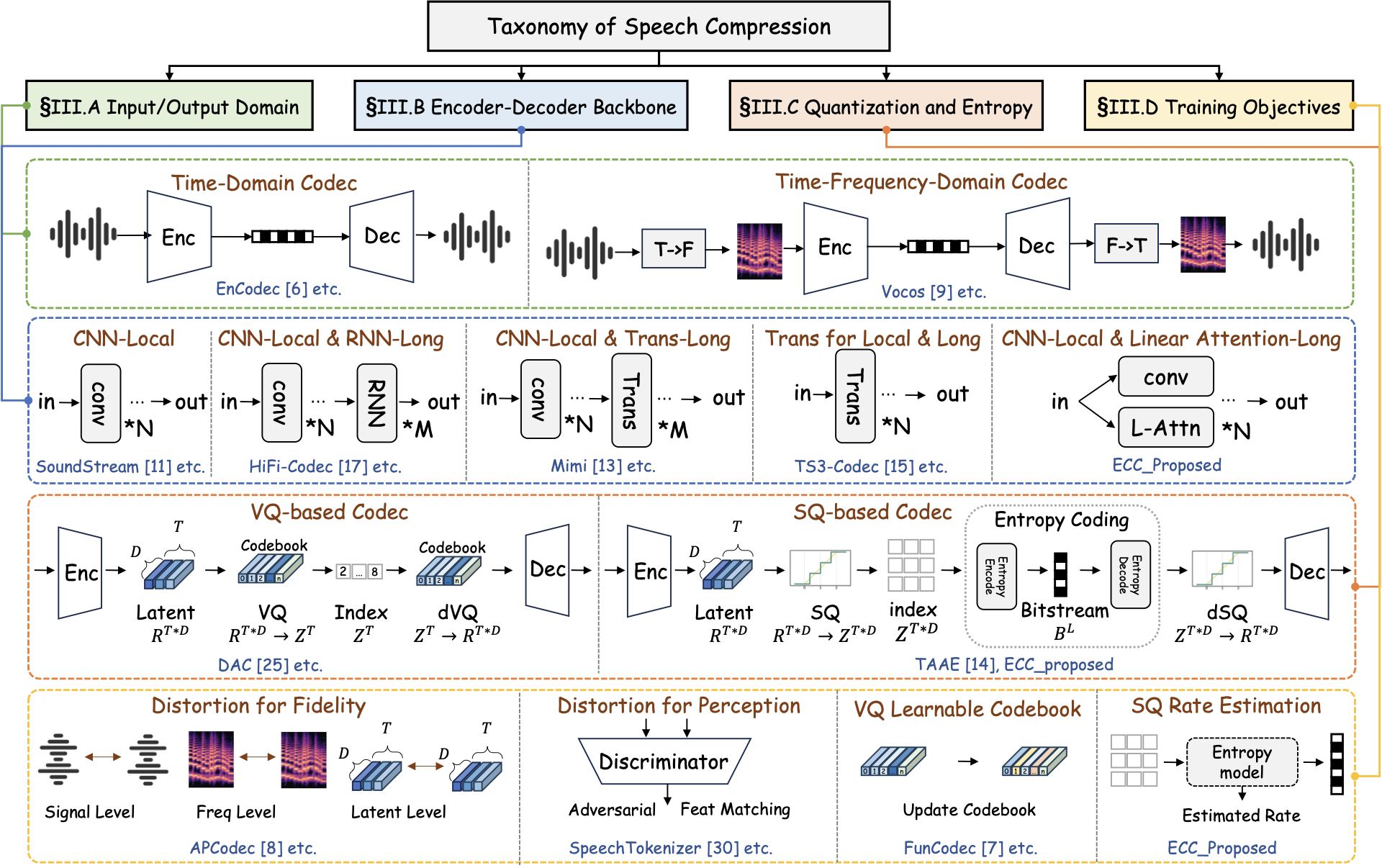
We organize recent learning-based speech codecs along four axes: input/output domain, encoder-decoder backbone, quantization and entropy coding, and training objectives. This taxonomy highlights how different codec designs represent speech signals, model temporal dependencies, construct discrete symbols, and handle coding costs.
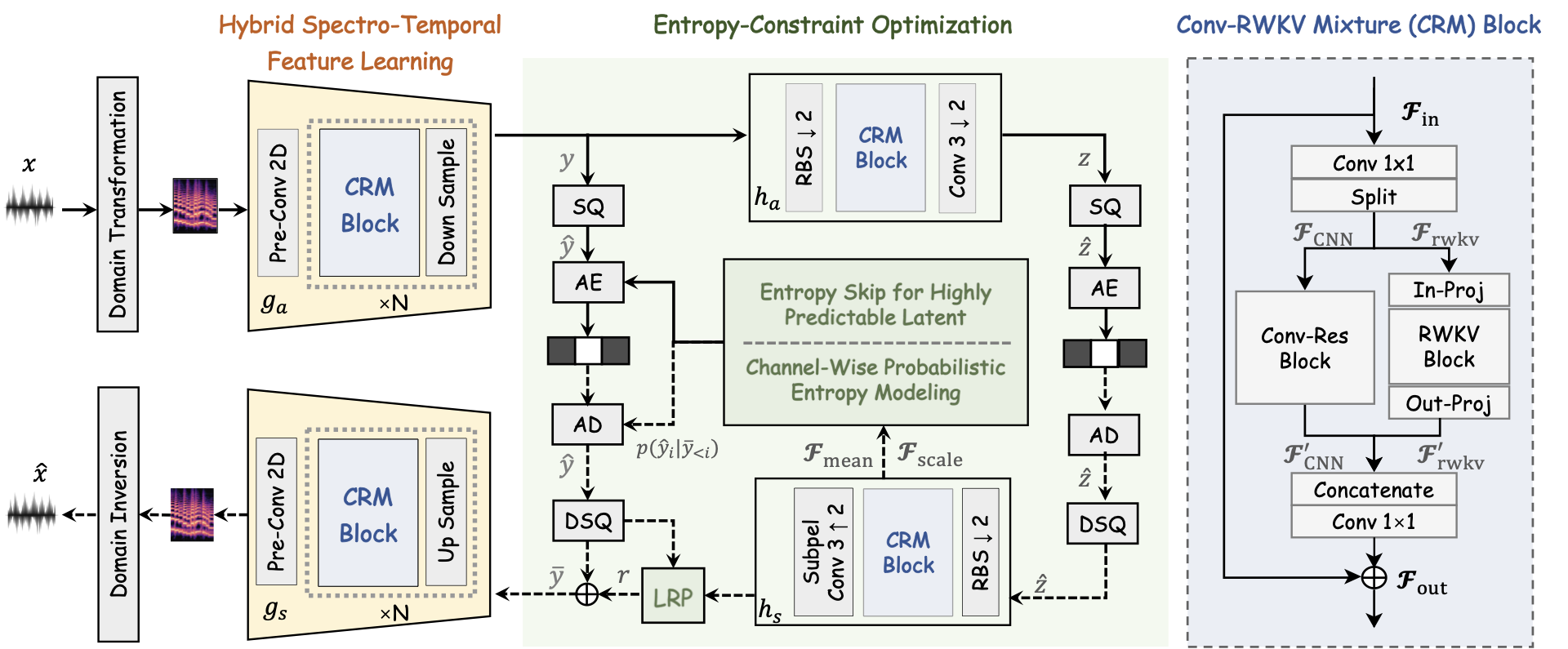
ECC jointly learns the analysis-synthesis transform, the latent probability model, and the reconstruction objective. The waveform is first converted into an STFT representation, then encoded into scalar latents whose probabilities are estimated from hyperprior features and decoded context for rate estimation during training and arithmetic coding during inference.
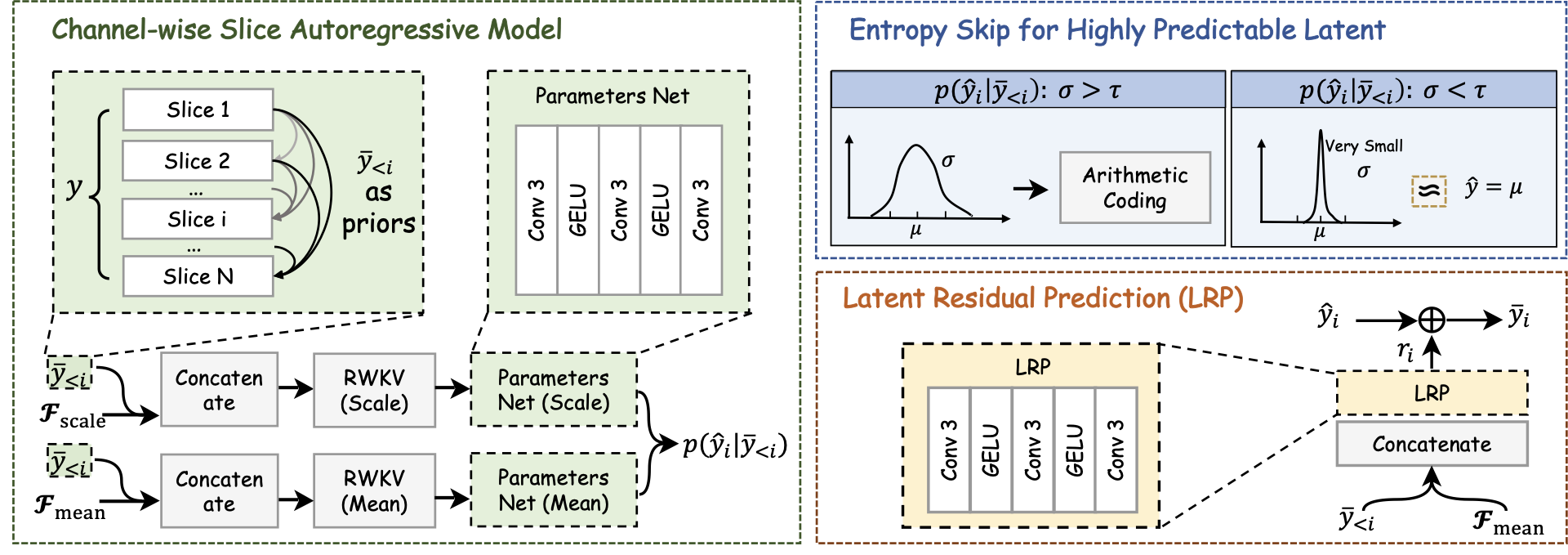
The channel-wise entropy model decodes hyper-latent side information into mean and scale features, then processes latent slices sequentially. For each slice, Gaussian parameters are predicted from the hyperprior features and previously decoded slices, while latent residual prediction refines the decoded slice before synthesis and subsequent context prediction.
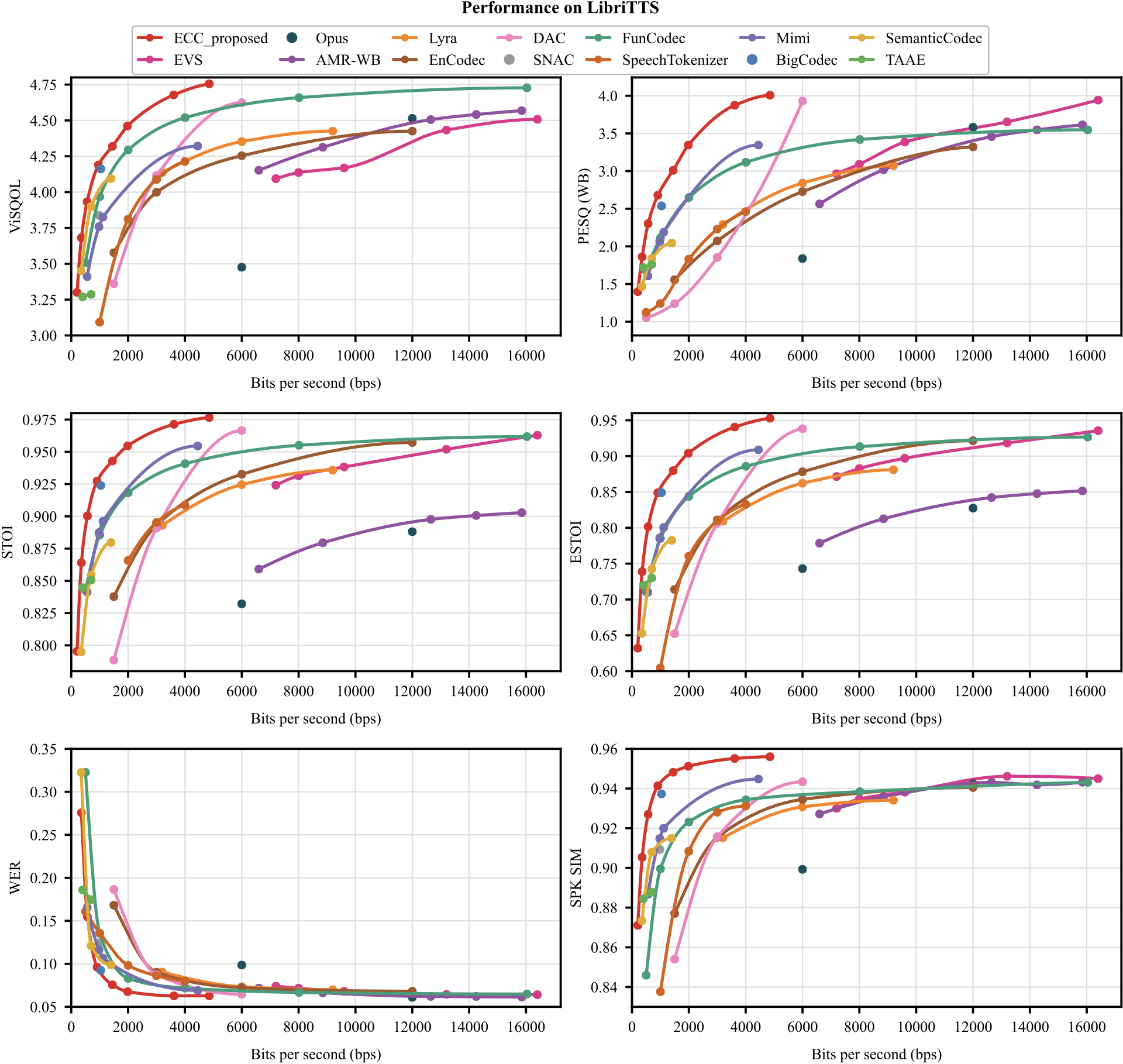
On LibriTTS test-all, ECC consistently occupies a favorable low-bitrate region across perceptual quality, intelligibility, recognition, and speaker-preservation metrics. This demonstrates the effectiveness of entropy-constrained scalar-latent coding on the in-domain evaluation set.
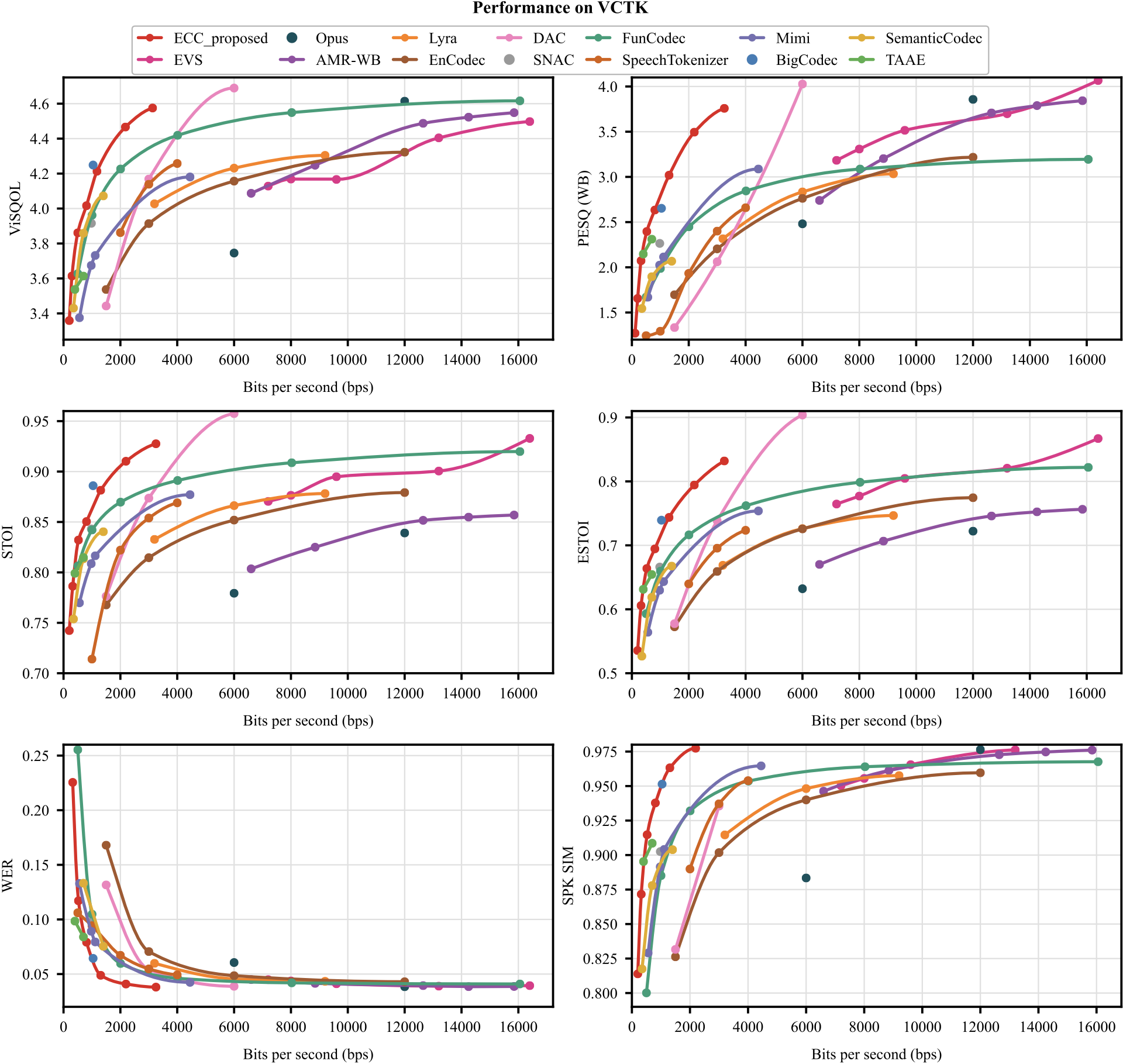
On VCTK, ECC preserves a similar low-bitrate advantage under speaker and recording-condition shifts, indicating that the learned representation and entropy model generalize beyond the LibriTTS training corpus.
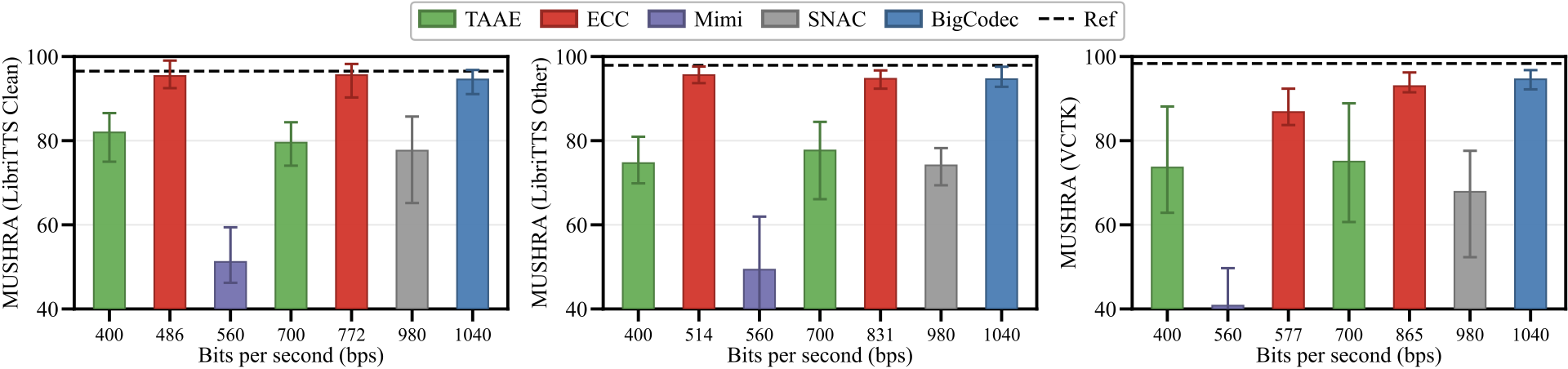
The MUSHRA listening test further confirms the low-bitrate perceptual quality of ECC. ECC obtains high subjective scores on LibriTTS test-clean, LibriTTS test-other, and VCTK, remaining close to the strongest competing neural codec while operating at a lower bitrate.
Audio Samples
Comparison of proposed method (ECC) with other methods across four datasets.